What is Machine Learning?

In an era defined by technological advancements and data-driven decision-making, Machine Learning (ML) stands at the forefront of innovation. It's a field that has transcended its niche origins to become a driving force behind many of the products and services we use daily. From personalized recommendations on streaming platforms to fraud detection in financial transactions, the applications of Machine Learning are as diverse as they are powerful.
But what exactly is Machine Learning, and why is it such a game-changer in the world of technology?
In this blog, we embark on a journey to unravel the mysteries of Machine Learning providing you with a comprehensive introduction to this fascinating field. Whether you're a curious newcomer or someone looking to deepen your understanding, this blog will guide you through the basics and beyond.
Machine Learning: A Paradigm Shift
ML is a subset of artificial intelligence (AI) that focuses on enabling computers to learn and make predictions or decisions based on data, without explicitly programming. In traditional programming, humans write code to instruct a computer to perform specific tasks. However, in ML, the computer learns patterns and rules from data, allowing it to generalize and make predictions or decisions on new, unseen data.
Imagine teaching a computer to recognize handwritten digits, understand spoken language, or even play complex games like chess or Go, without explicitly programming all the rules. That's the power of ML.
Why use Machine Learning?
Today's world is awash with data - from the digital footprints we leave on social media to the terabytes of information generated by industries like healthcare and finance. ML harnesses this wealth of data to extract insights, automate tasks, and make predictions with unprecedented accuracy.

Here are a few reasons why ML has become indispensable:
- Data-Driven Decision-Making: ML models can sift through vast datasets to identify trends and patterns humans might miss. This data-driven approach is invaluable in making informed decisions.
- Automation: By automating repetitive tasks, ML frees up human resources for more creative and strategic work. This is particularly relevant in industries like manufacturing and customer services.
- Personalization: Think about how Netflix recommends movies tailored to your tastes or how Amazon suggests products that you might like. ML algorithms power these recommendations, enhancing user experiences.
- Healthcare Advancements: ML is transforming healthcare by assisting in diagnostics, predicting disease outbreaks, and optimizing treatment plans.
- Financial Services: In the financial sector, ML is used for fraud detection, algorithmic trading, and credit risk assessment, among other applications.
Where can Machine Learning be applied?
Let's look at some concrete examples of ML tasks, along with the techniques that can tackle them:
- Analyzing images of products on a production line to automatically classify them - this is image classification, typically performed using Convolutional Neural Networks (CNN).
- Detecting tumors in brain scans - each pixel in the images is classified to determine the exact location and shape of tumors, typically using CNNs.
- Automatically classifying news articles - this is Natural Language Processing (NLP), and more specifically text classification performed using Recurrent Neural Networks (RNNs), CNNs, or Transformers.
- Automatically flagging offensive comments on discussion - text classification using the same NLP tools.
- Creating a chatbot or a personal assistant - this involves many NLP components, including natural language understanding (NLU) and question-answering modules.
- Making your app react to voice commands - this is speech recognition, which requires processing audio samples. Since they are long and complex sequences, typically processed using RNNs, CNNs, or Transformers.
- Recommending a product that a client may be interested in, based on past purchases - this is a recommender system.
The list could go on and on, but hopefully, it gives you a sense of the incredible breadth and complexity of the tasks that ML can tackle, and the types of techniques that you would use for each task.
Types of Machine Learning Systems
There are so many different types of ML systems that it is useful to classify them in broad categories, based on the following criteria:
- Whether or not they are trained with human supervision (Supervised, Unsupervised, Semi-supervised, Reinforcement Learning)
- Whether or not they can learn incrementally on the fly (Online vs. Batch Learning)
- Whether they work by simply comparing new data points to known data points, or instead by detecting patterns in the training data and building a predictive model, much like scientists do (Instance-based vs. Model-based Learning)
Supervised/ Unsupervised Learning
Supervised Learning
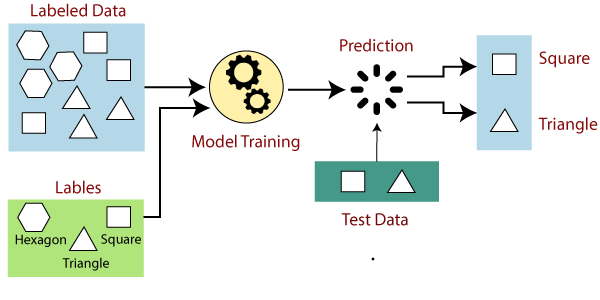
In supervised learning, the algorithms learn from a labeled dataset, which means each training example is paired with the correct output. The goal is to learn a mapping function from inputs to outputs so that the model can make accurate predictions on unseen data.
A typical supervised learning task is classification. The spam filter is a good example of this.
Another typical task is to predict a target numeric value, such as the price of a car, given a set of features (mileage, age, brand, etc.) called predictors. This sort of task is called regression.
Here are some of the most important supervised learning algorithms:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines (SVMs)
- Decision Trees and Random Forests
- Neural Networks
Common applications include - image classification, spam mail detection, and predicting housing prices.
Challenges - the need for large labeled datasets, potential bias in training data, and selecting appropriate model architectures and hyperparameters.
Unsupervised Learning
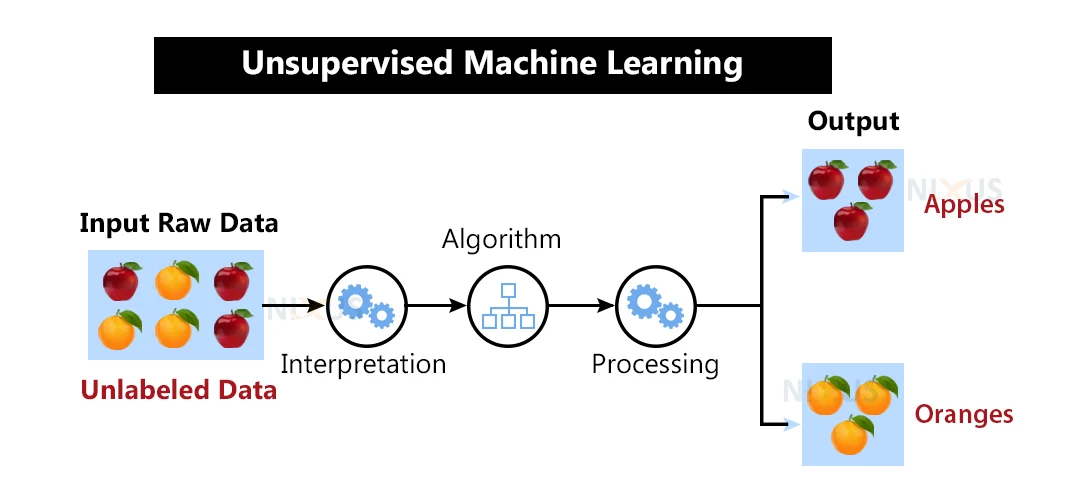
Unlike supervised learning, unsupervised learning deals with unlabeled data. The primary goal is to discover patterns, structures, or representations within the data without any specific target variable. Common techniques include - clustering, dimensionality reduction, and generative modeling. Examples include - customer segmentation and topic modeling.
Here are some of the most important unsupervised learning algorithms:
- Clustering:
- K-Means,
- DBSCAN,
- Hierarchical Cluster Analysis (HCA)
- Anomaly detection and novelty detection:
- One-class SVM,
- Isolation Forest
- Visualization and dimensionality reduction:
- Principal Component Analysis (PCA),
- Kernel PCA
- Association Rule Learning:
- Apriori,
- Eclat
Challenges - determining the number of clusters or components, evaluating the quality of learned representations, and interpreting the discovered patterns.
Semisupervised Learning
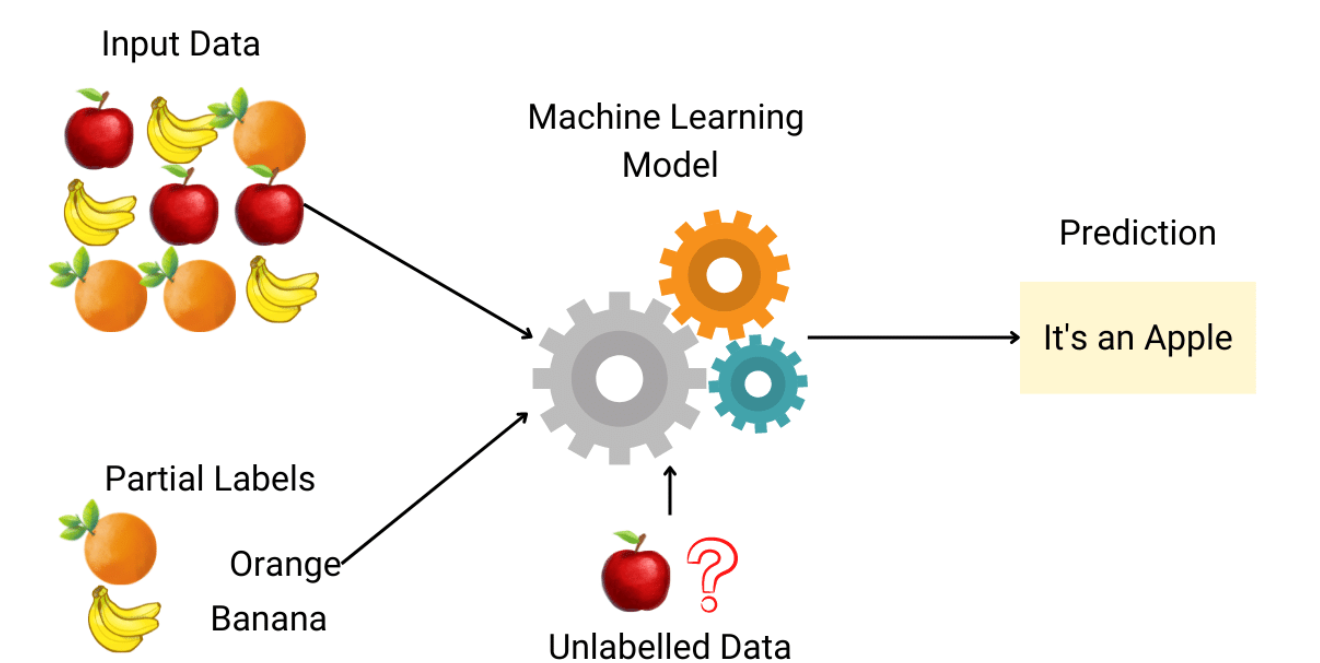
Since labeling data is usually time-consuming and costly, you will often have plenty of unlabeled instances, and few labeled instances. Some algorithms can deal with data that's partially labeled. This is called semisupervised learning.
Most semisupervised learning algorithms are combinations of unsupervised and supervised algorithms. For example, deep belief networks (DBNs) are based on unsupervised components called Restricted Boltzmann Machines (RBMs) stacked on top of each other. RBMs are trained sequentially in an unsupervised manner, and then the whole system is fine-tuned using supervised learning techniques.
Reinforcement Learning
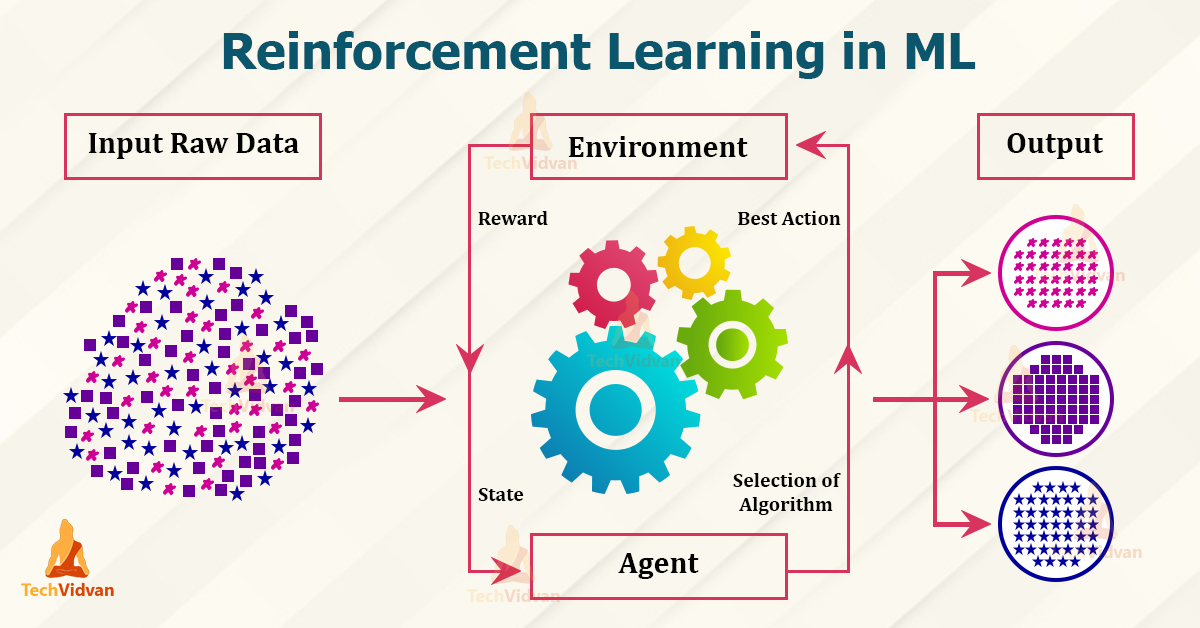
Reinforcement learning is about training agents to interact with an environment and learn optimal actions to maximize a reward signal. It is often used in scenarios where an agent must make a sequence of decisions, such as in robotics, game-playing (e.g., AlphaGo), and autonomous vehicles. It involves explorations and exploitation trade-offs and can use techniques like Q-learning and deep reinforcement learning.
Challenges - designing reward functions, dealing with exploration vs. exploitation dilemmas, and handling high-dimensional state and action spaces.
Batch and Online Learning
Batch Learning
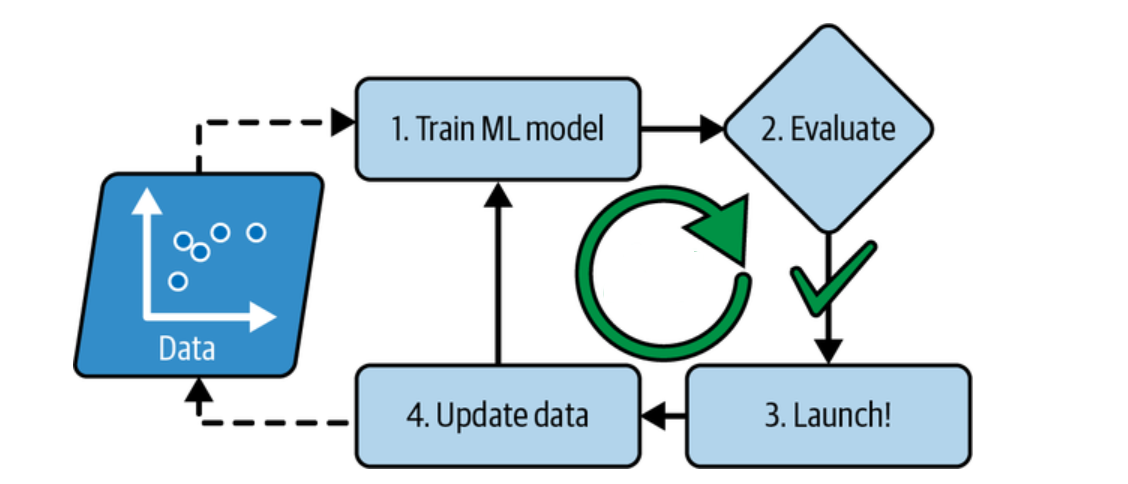
Batch Learning involves training a model on the entire dataset at once. It calculates gradients based on the entire dataset and updates the model's parameters accordingly. It is suitable for scenarios where the dataset fits in memory, and model updates can be performed periodically.
Challenges - memory and computational requirements for large datasets and the need to retrain the model when new data arrives.
Online Learning
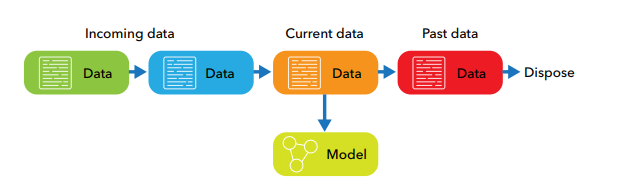
Online learning, also known as incremental learning or streaming learning, processes data one example at a time and updates the model after each data point. It is well-suited for scenarios with continuous data streams, where the model needs to adapt to changing patterns quickly.
Challenges - dealing with the concept drift (changes in data distribution over time), selecting appropriate learning rates, and ensuring model stability.
Instance-Based Versus Model-Based Learning
Instance-based Learning
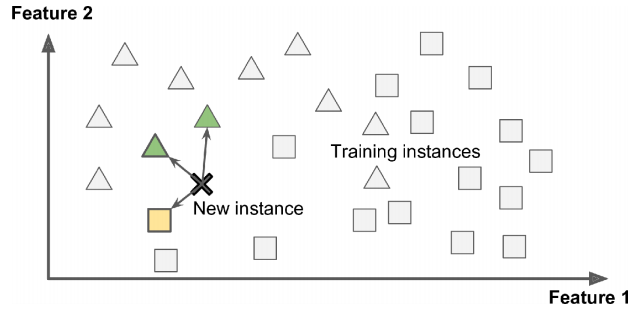
Instance-based learning methods store and memorize the training instances and make predictions based on their similarity to new examples. K-Nearest Neighbors (k-NN) is a classic instance-based algorithm. These methods can be effective when the relationship between inputs and outputs is complex and not easily captured by a model.
Challenges - include high memory requirements for storing instances and computational overhead in finding nearest neighbors.
Model-based Learning
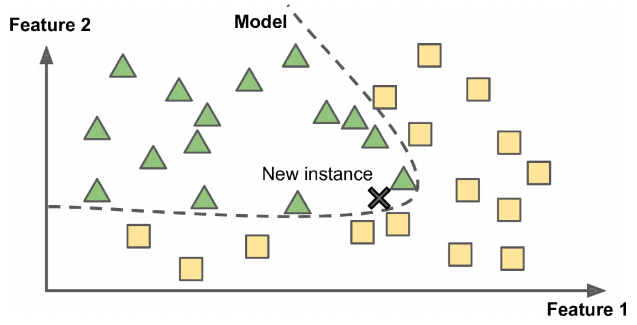
Model-based learning involves learning a compact representation or model of the data's underlying structure. This model is then used to make predictions or generate new data. Linear regression, decision trees, and neural networks are examples of model-based approaches.
Challenges - including selecting the appropriate model architecture, training it effectively, and interpreting the learned parameters.
Main Challenges of Machine Learning
Insufficient Quantity of Training Data
For a toddler to learn what an apple is, all it takes is for you to point to an apple, and say "apple" (possibly repeating this procedure a few times). Now the child is able to recognize apples in all sorts of colors and shapes. Genius!
ML is not quite there yet; ML models rely heavily on data for training. When there isn't enough data available, models may struggle to learn meaningful patterns and generalize effectively. This can lead to poor performance, especially in complex tasks.
Gathering more data or employing data augmentation techniques can help mitigate this challenge.
Nonrepresentative Training Data
The quality of training data is crucial. If the data used for training doesn't accurately represent the real-world scenarios the model will encounter, it can result in biased or inaccurate predictions.
To address this challenge, it's essential to carefully curate and balance the training dataset to ensure it reflects the diversity of the problem domain.
Poor-Quality Data
Data quality is paramount in ML. Noisy, incomplete, or inconsistent data (e.g., due to poor-quality measurements) can lead to subpar models.
Preprocessing steps such as data cleaning, normalization, and handling missing values are essential to ensure the data's reliability and consistency.
Irrelevant Features
As the saying goes: garbage in, garbage out. Including irrelevant features in the dataset can hinder model performance. These features can introduce noise and make it more challenging for the model to discern meaningful patterns.
Feature selection (selecting the most useful features to train on among the existing features); feature extraction (combining existing features to produce a more useful one); creating new features by gathering new data; or engineering techniques help identify and remove or transform irrelevant features.
Overfitting the Training Data
Say you are visiting a foreign country and the taxi driver rips you off. You might be tempted to say that all taxi drivers in that country are thieves. Overgeneralization is something that we humans do all too often, and unfortunately, machines can fall into the same trap if we are not careful.
Overfitting occurs when a model learns to perform exceptionally well on the training data but fails to generalize to unseen data. This is often a result of a model being too complex relative to the amount of training data.
Techniques like cross-validation, regularization, and reducing model complexities can combat overfitting.
Underfitting the Training Data
Conversely, underfitting happens when a model is too simple to capture the underlying patterns in the data. It results in poor performance on both the training and test data.
To mitigate underfitting, you may need to use more complex models with more parameters or collect additional features that better represent the problem.
Addressing these challenges is crucial for building robust and reliable ML models. Moreover, these challenges highlight the iterative and often experimental nature of ML. Data scientists and practitioners need to continuously refine their models, fine-tune hyperparameters, and adapt their approaches to overcome these obstacles.
Testing and Validating
The only way to know how well a model will generalize to new cases is to actually try it out on new cases.
The total data is split into two sets: the training dataset and the test dataset. As these names imply, you train your model using the training set, and you test it using the test set. The error rate on new cases is called the generalization error (or out-of-sample error), and by evaluating your model on the test set, you get an estimate of this error. This value tells you how well your model will perform on instances it has never seen before.
If the training error is low (i.e., your model makes few mistakes on the training set) but the generalization error is high, it means that your model is overfitting the training data.
Hyperparameter Tuning and Model Selection
ML models often come with various hyperparameters that are not learned from the training data but must be set beforehand. Examples include - learning rate in neural networks, the number of trees in a random forest, or the depth of a decision tree.
Challenges:
- The Curse of Dimensionality: As the number of hyperparameters and possible values increases, the search space for finding the optimal combination grows exponentially.
- Overfitting: During hyperparameter tuning, there's a risk of overfitting the validation data, which can lead to poor generalization of unseen data.
Strategies to Address the Challenges:
- Grid Search and Random Search: these techniques systematically explore different combinations of hyperparameters. Grid search tests all possible combinations within predefined ranges, while random search randomly samples combinations.
- Cross-Validation: to prevent overfitting during hyperparameter tuning, cross-validation is crucial. It involves dividing the data into multiple subsets (folds) and training and validating the model on different combinations of these subsets.
Data mismatch
Data mismatch occurs when there are significant differences between the data used for training and the data encountered during deployment. These differences can arise due to changes in the data distribution over time, variations in data collection processes, etc.
Challenges:
- Performance Degradation: A model trained on one distribution may perform poorly when faced with a different distribution, leading to unexpected and costly errors.
- Concept Drift: In dynamic environments (e.g., financial markets or medical diagnosis), the underlying relationships between features and outcomes may change over time.
Strategies to Address the Challenges:
- Continuous monitoring: Regularly monitoring the model's performance and retraining it as needed to adapt to changing data distributions. This may involve updating the model with new data or fine-tuning hyperparameters.
- Transfer Learning: Transfer Learning techniques, such as using pre-trained models and fine-tuning them on domain-specific data, can be valuable in scenarios where labeled data for the target distribution is limited.

In our exploration of Machine Learning, we will delve further into these topics and provide practical guidance on how to handle these challenges effectively. Stay tuned for more insights and best practices in the exciting world of Machine Learning.
Pic courtesy: Google
Comments
Post a Comment